本文档为OSH-2023 My-Glow小组的Lab4文档。
Ray 部署文档
环境配置
- Ubuntu版本:22.04.2
- python版本:3.10.10
- pip版本:23.0.1
单机版Ray部署
安装Ray
Ray的安装基于pip。运行以下命令安装Ray:
1 | sudo apt update |
自动安装了ray2.3.1版本。
根据官方文档,运行
sudo pip3 install -U ray也可;与安装ray[default]的区别在于ray[default]会多安装一些依赖。
Ray cluster部署
Ray集群的部署要求集群内的机器在同一局域网下,并且python和Ray版本相同。
在主节点上:运行如下命令:
1
ray start --head --port=6379
得到如下输出,则Ray启动成功:
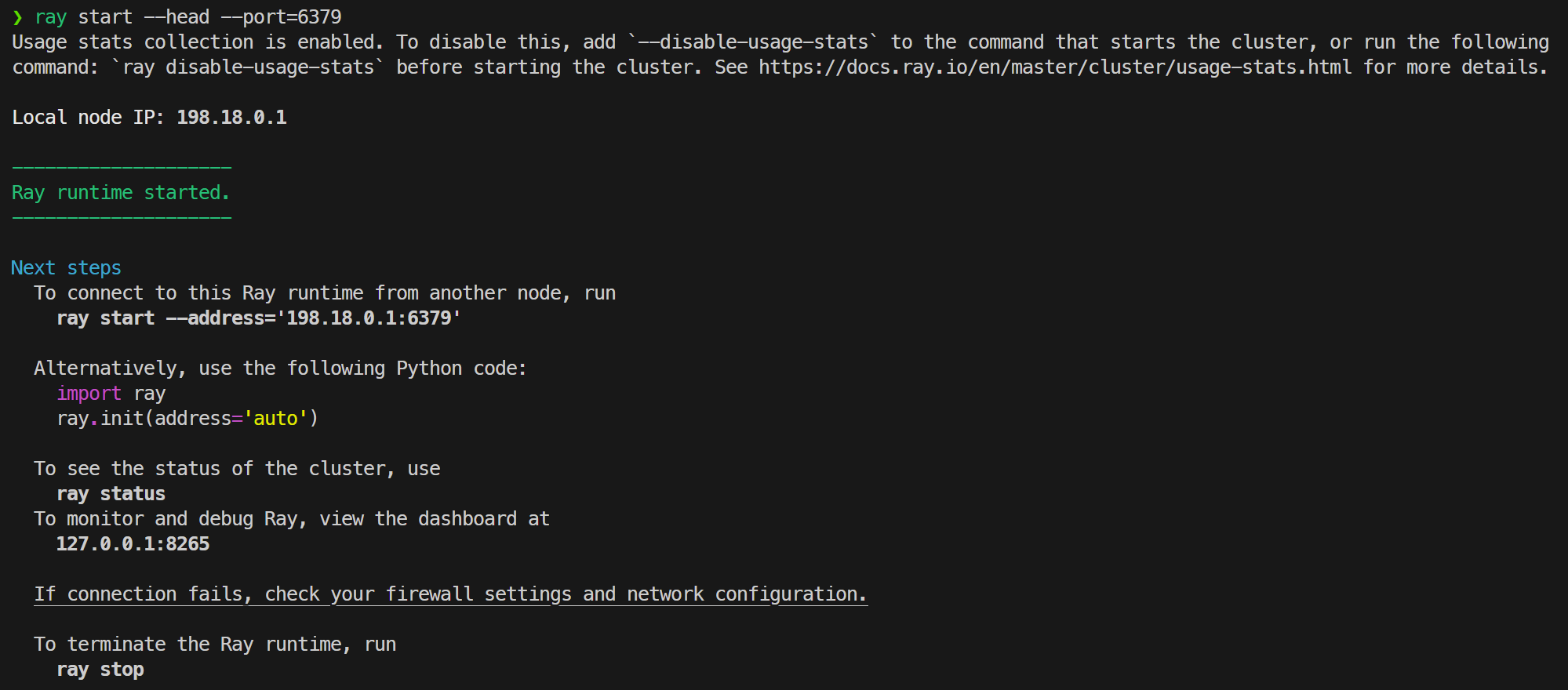
在子结点上:运行如下命令:(该命令即为主节点上运行时输出的命令)
1
ray start --address='198.18.0.1:6379'
得到如下输出,则Ray子结点已连接到主节点上:
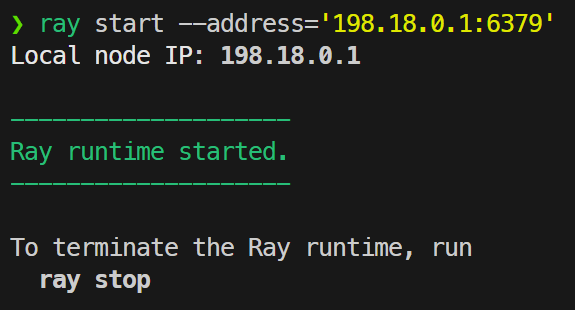
要结束ray,只需在主节点上运行
ray stop即可。
Ray监控
在主节点上登陆localhost:8265即可看到所有节点的监控信息。
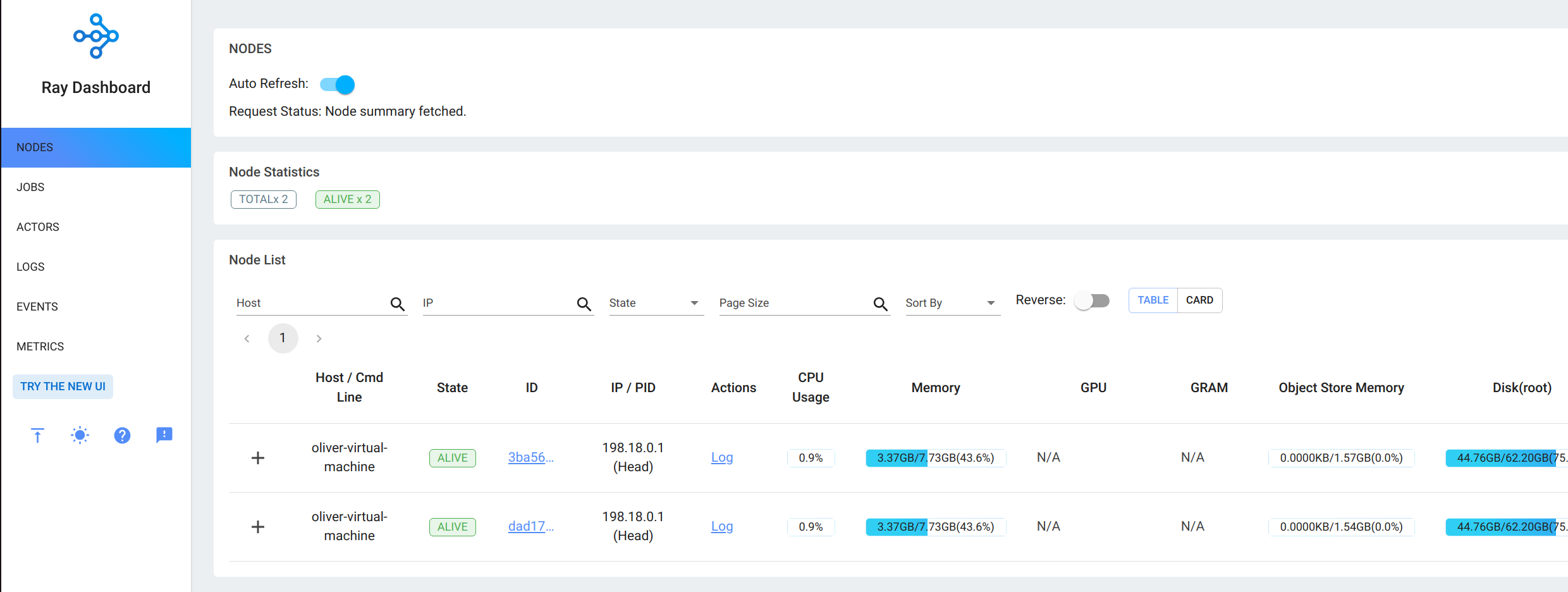
这里使用了旧ui。
docker部署Ray
首先docker的安装见官方文档,换源见中科大docker镜像
Dockerfile如下:
1 | FROM ubuntu |
使用该镜像来创建ray镜像。步骤如下:
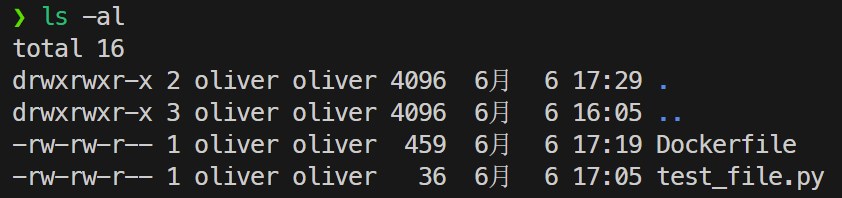
在目录下创建Dockerfile,并将测试的python文件复制到同一文件夹下,如下图:
构建docker镜像:
1
docker build -t ray_cluster .
-t参数的目的是将打包的镜像文件命名。
运行docker镜像:
头结点:
1
docker run -idt --name ray_head ray_cluster
子结点:(此处子结点开启了两个,可按需求开启)
1
2docker run -idt --name ray_node1 ray_cluster
docker run -idt --name ray_node2 ray_cluster-d参数的目的是后台执行容器;-it使得容器不会自动退出,并能够通过终端访问。
进入容器,并开启/连接Ray服务
对于头结点:
1
2
3docker exec -it ray_head bin/bash
# 以下为容器内部操作
ray start --head --port=6379可以得到与单机版部署类似的输出。
对于子结点:
1
2
3
4docker exec -it ray_node1 bin/bash
# 以下为容器内部操作
# address为头结点输出的地址
ray start --address='172.17.0.2:6379'在头结点内运行测试文件即可开始测试。
Ray性能测试与优化
测试任务
我们组选用的测试任务是计算一定范围内(暴力计算)质数的个数。
选用该任务的原因是该任务计算量大,能够体现出分布式计算的优点;同时暴力计算便于并行化,程序编写简单,且运行时间适中,避免偶然因素影响实验结果。
暴力计算素数个数的核心代码如下:
1 | def is_prime(n: int): |
Ray性能指标
性能指标如下:
CPU占用率:指计算任务在CPU上的负载。
CPU占用率代表了任务在不同节点内对CPU的压力。
总执行时间:指同一程序从开始执行到执行完毕的时间。
总执行时间代表了一项任务分配在不同节点后的性能表现。
平均响应时间:指系统对请求做出响应的平均时间
平均响应时间代表了一个系统对大量请求的处理能力;在Ray系统内可指代从程序开始执行到Ray开始真正计算的间隔。
吞吐量:指系统在单位时间内处理请求的数量。
吞吐量代表了一个系统单位时间内能够处理请求的数量。
响应时间方差:指将所有节点的响应时间排成数列,该数列的方差。
响应时间方差从另一方面代表了一个系统对大量请求的处理能力;如果方差过大,则代表该系统分配任务存在不均衡的情况,该系统的性能大概率会比较低。
在本实验中,我们将监测CPU占用率和总执行时间两个指标;原因是这两个指标易于测量:CPU占用率可以从Ray控制台上直接得到;总执行时间可以在程序中计时得到。
程序计时测量执行时间可能存在系统误差,但拉长执行时间后该系统误差会被稀释,对整体的影响较小,因此可以使用。
不使用Ray进行测试
CPU使用率测试结果如下:(使用top监测)
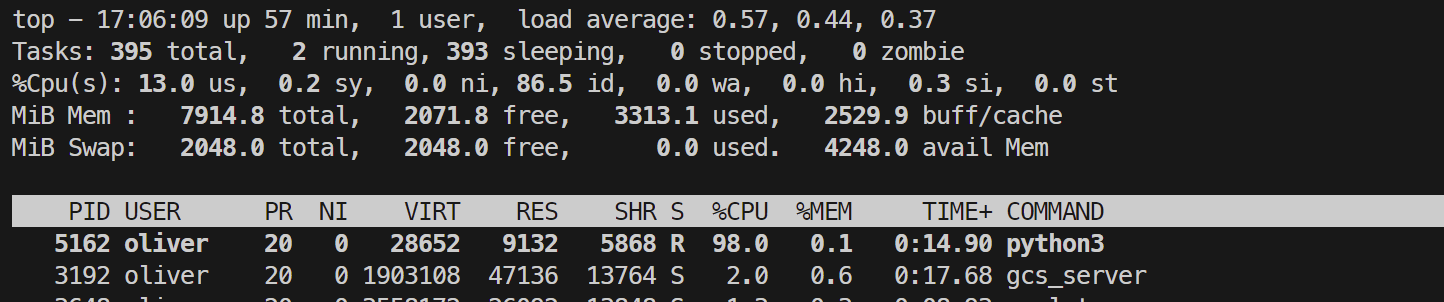
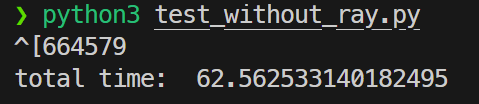
总执行时间时间测试结果如下:
上述结果汇总为表格如下:
| 运行平台 | CPU占用率 | 执行时间 |
|---|---|---|
| 不使用Ray | 98%+(单核) | 62.56s |
该结果将作为使用Ray测试时的性能基准。
Ray单机性能测试
核心代码
1 |
|
在一台虚拟机上运行一个头结点和两个子结点,作为Ray集群。
测试
运行计算质数个数的代码,得到如下结果:

运行过程中Ray的控制台如下所示:
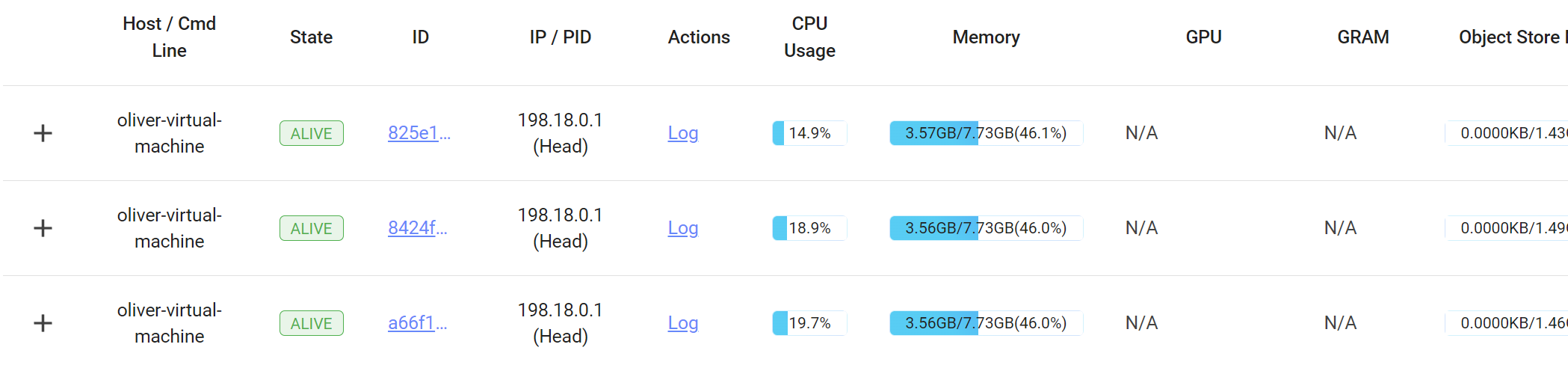
观测top内CPU的使用率如下:

top内显示Ray计算只用了一个进程,显然没有对多核计算进行优化。
总结出单机运行Ray的性能指标如下表所示:
| 运行平台 | CPU占用率 | 执行时间 |
|---|---|---|
| 不使用Ray | 98%+(单核) | 62.56s |
| 使用Ray | <20%(所有核)~100%(单核) | 64.32s |
可以看到,程序部署在Ray后,运行时间相比未部署的时间反而长了2s(应为Ray分配任务的开销),且CPU的利用率仅不到20%,说明上述代码并没有利用到Ray分布式集群强大的运算能力,应该进行优化。
Ray单机优化性能测试
针对上述代码无法利用到Ray性能的问题,考虑将测试代码进行优化。
最初的测试代码只是将任务整体交给Ray,因此用不到Ray的并行计算。因此,在计算任务中,将所有任务手动拆分为小块,并分配给Ray,性能预期将会提升。
修改main函数如下所示:
1 | def main(): |
代码将待测试的所有数分为10组,并调用多个remote()方法生成多个计算实例并同时计算,从而达到更高的计算性能。
测试结果如下所示:

运行过程中Ray的控制台如下所示:
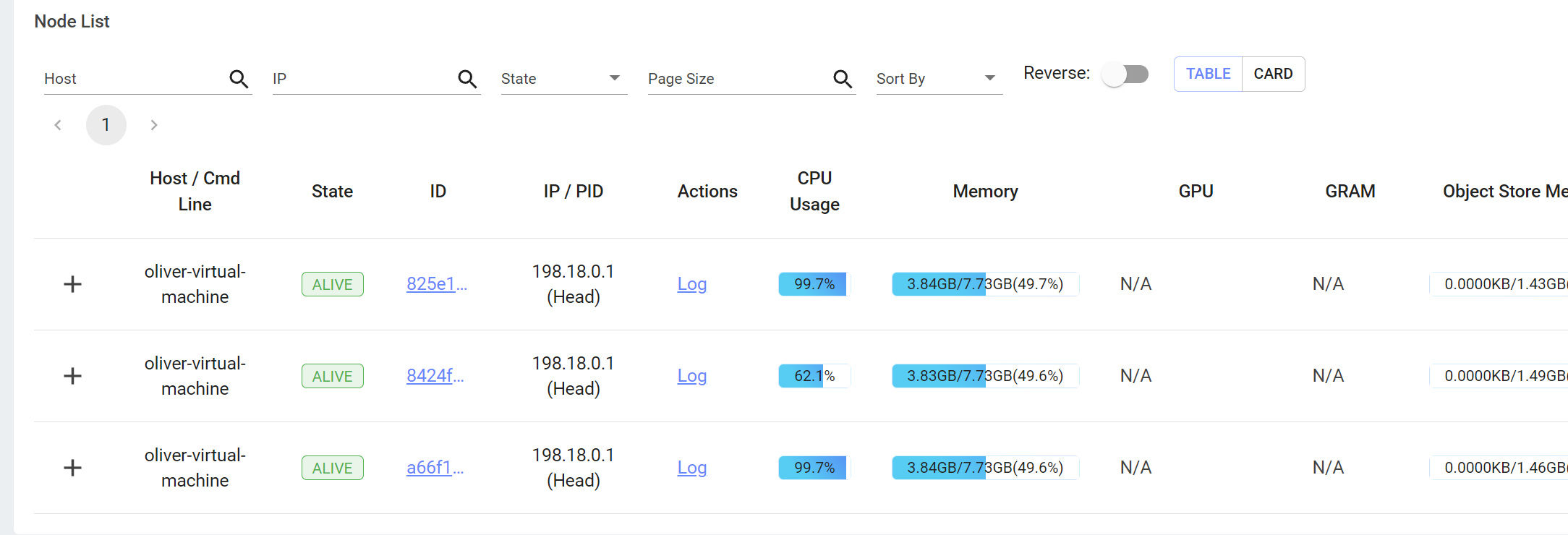
图中显示第二个节点CPU使用率显著低于其他两个节点,可能原因是其正处于被分配过程中,因此可视为误差。
观测top内CPU的使用率如下:
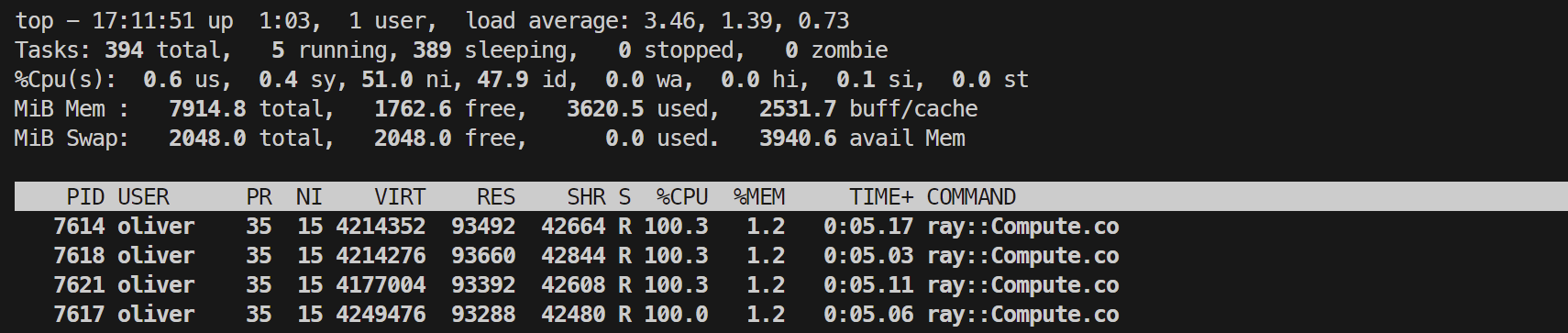
可见Ray自动开启了多个compute进程,提高了运算速度。
由上述所有总结出单机运行Ray的性能指标如下表所示:
| 运行平台 | CPU占用率 | 执行时间 |
|---|---|---|
| 不使用Ray | 98%+(单进程) | 62.56s |
| 使用Ray | <20%(对任一节点)~100%(单进程) | 64.32s |
| 使用Ray(代码已优化) | 99%+(对任一节点) ~100%(多进程) | 20.82s |
优化过后代码的性能提升约为3倍,说明利用到并行的代码得到了质的性能提升。
Ray分布式性能测试
分布式测试在两台虚拟机上进行。在一台虚拟机上运行Ray的头节点,在另一台虚拟机上运行子结点,从而构成Ray集群。
Ray的控制台如下所示:

两节点的IP地址不同可以证明Ray集群是在两台机器上搭建的。
在头结点运行测试程序,得到如下结果:
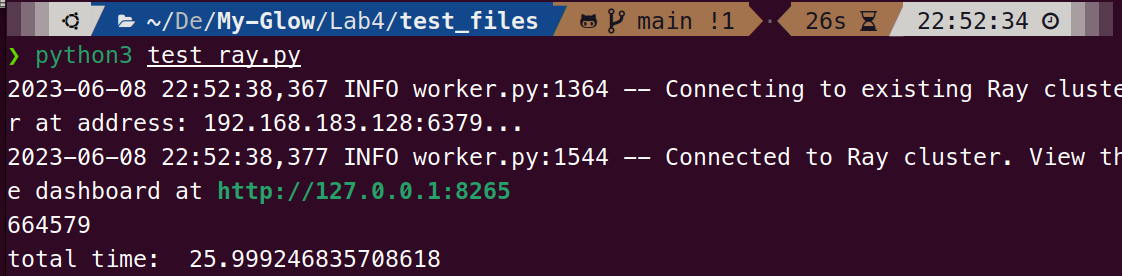
观察到两台虚拟机的CPU使用率如下,即CPU负荷均达到最大:
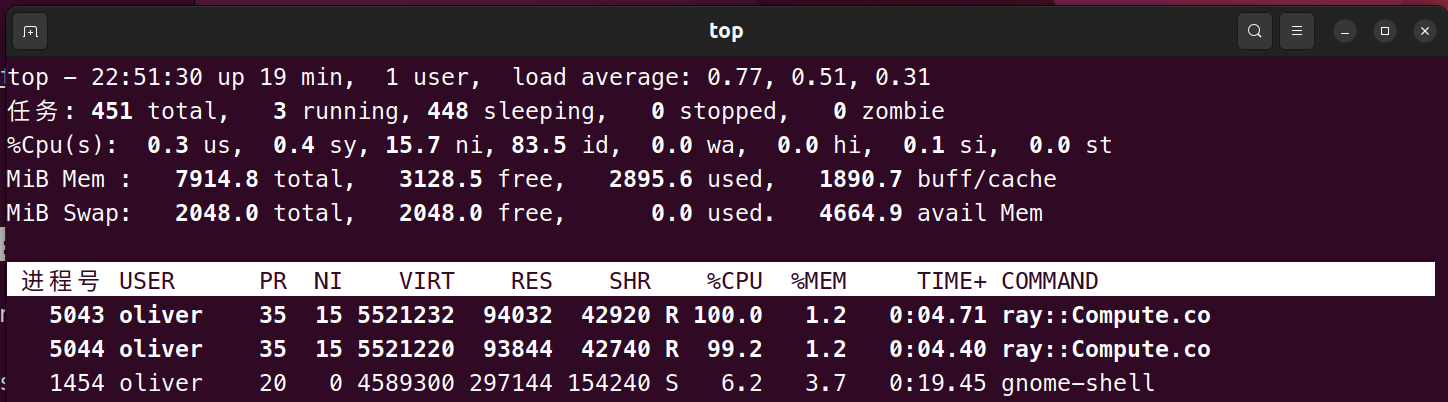
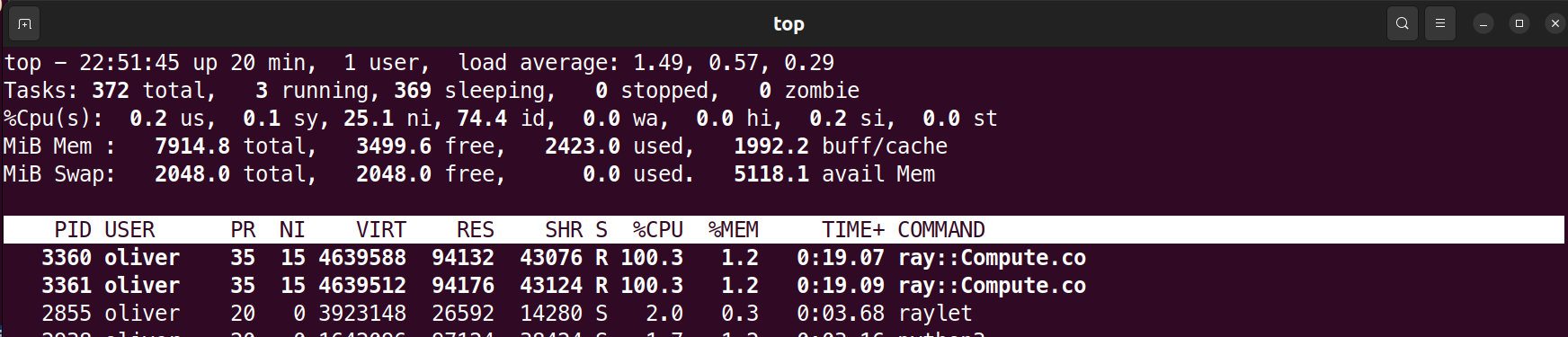
Ray的控制台输出如下所示:

由上述测试结果可以得到Ray已经在多机上完成了分布式部署。
Docker部署性能测试
Docker的部署过程见部署文档。在完成部署文档的内容后,机器中应该已经有Docker的镜像了。
在终端1上运行docker镜像,并在内部的终端中运行ray start --head --port=6379,得到如下输出:
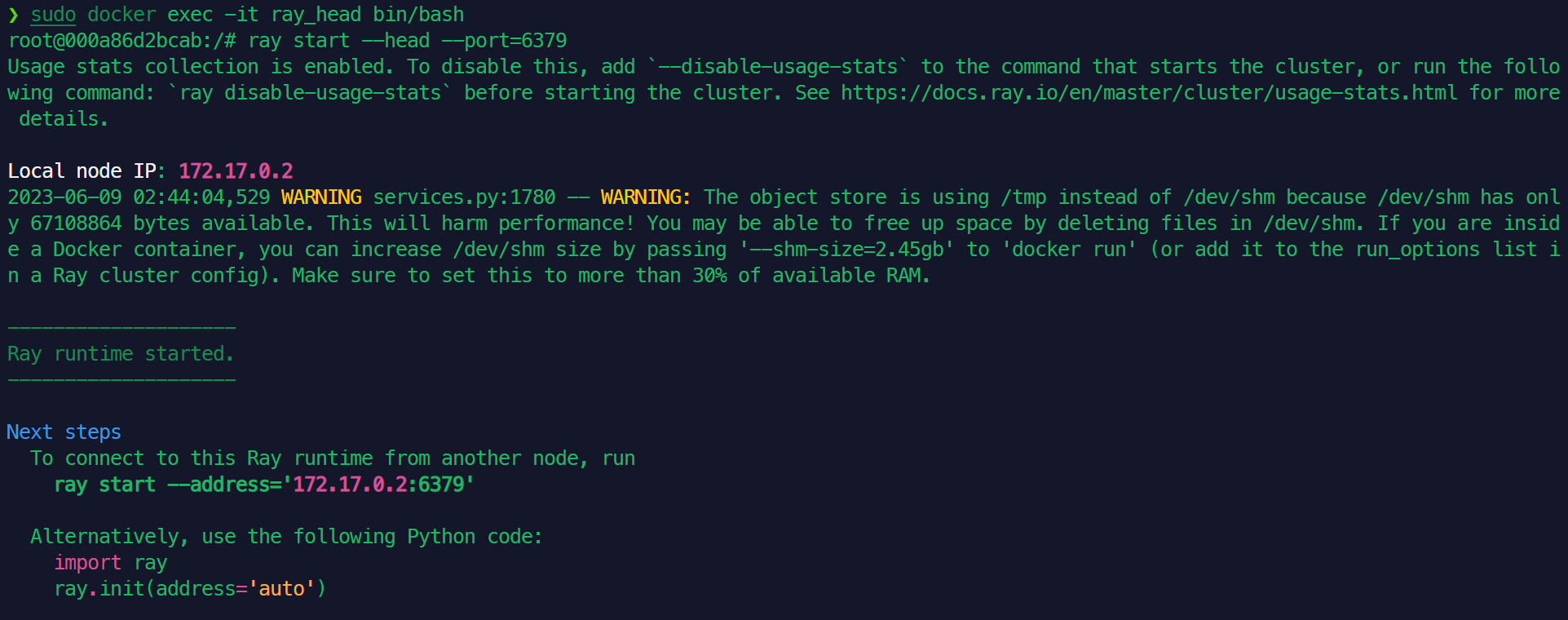
类似的,在终端2的docker内运行ray start --address='172.17.0.2:6379',有以下输出:
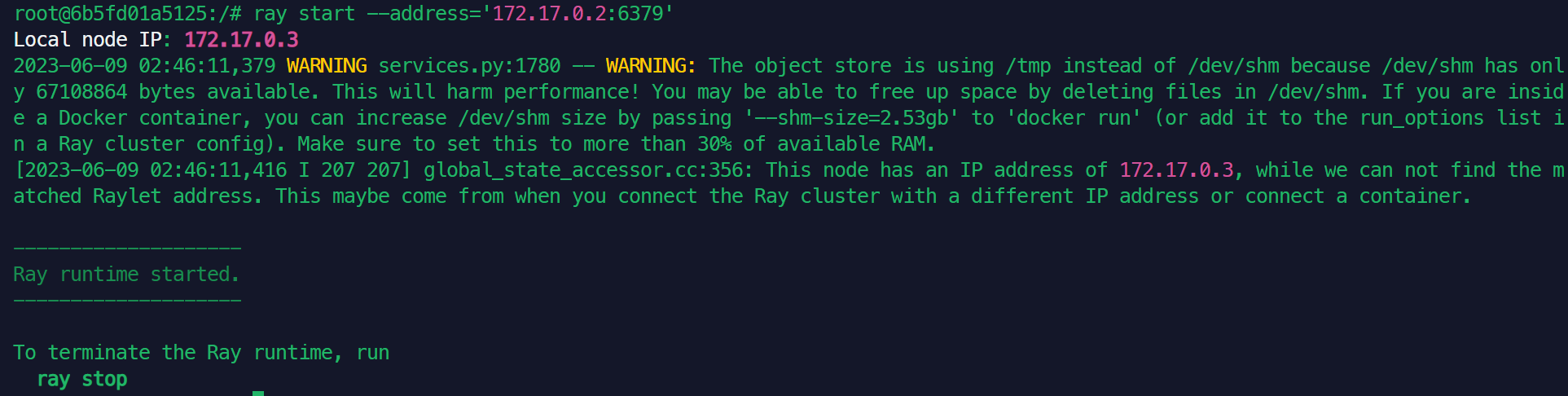
由于docker内无法通过浏览器显示ray控制台,因此在头结点内使用ray status查看集群的状态:
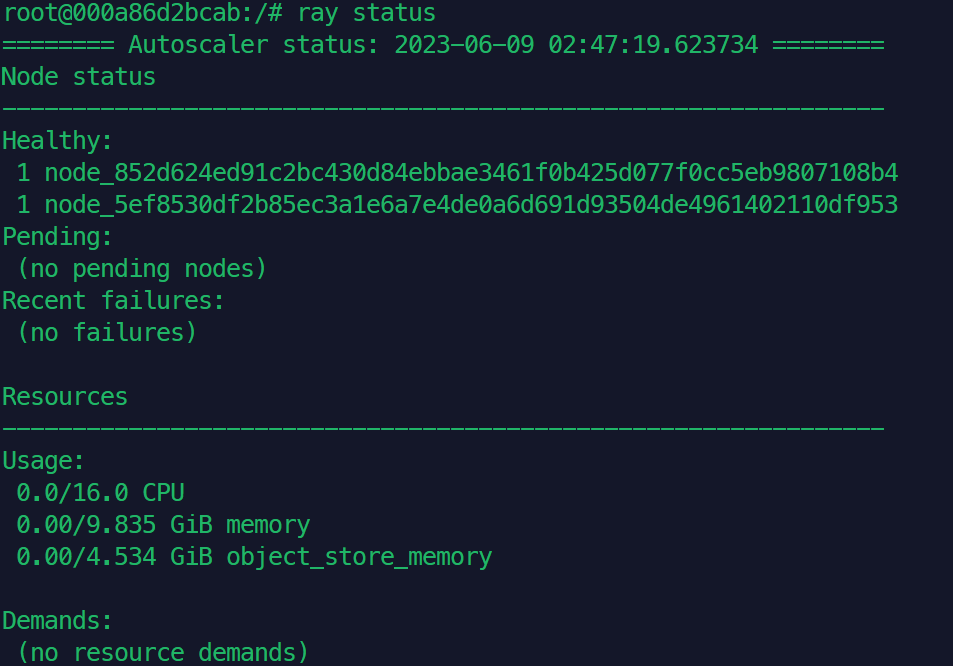
可见在docker搭建的ray集群内有两个节点,即两台终端分别对应的节点。
在头结点内运行测试文件,得到如下输出:

这个结果与单机上部署多个ray节点测试结果类似,说明在docker上部署是成功的。