相较于传统的搜索引擎和推荐系统是在被动的筛选信息,LLM能够积极主动的探索用户意图,通过多轮交互来确定用户的喜好和兴趣。
eg. 推荐系统中:基于内容的推荐是无法捕获用户偏好的,可以考虑LLM改进。
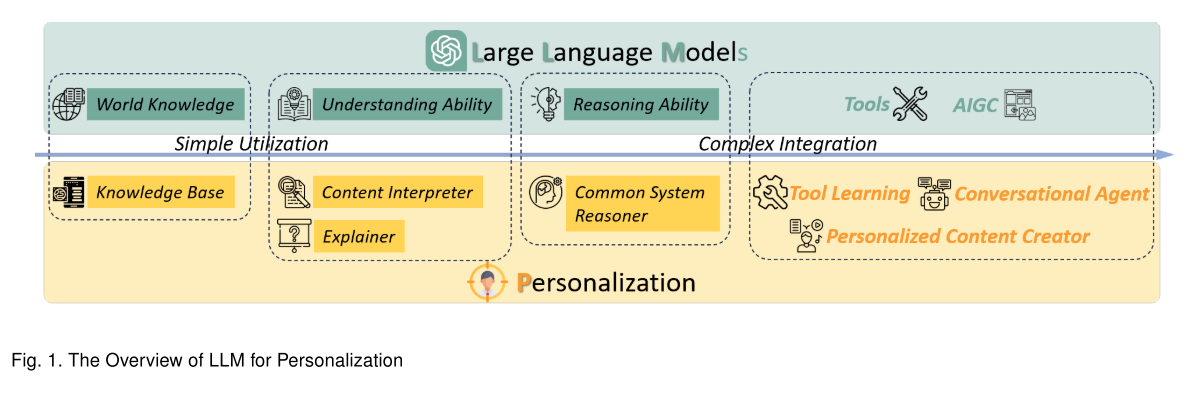
LLM作为知识库
首先,可以直接通过三元组的头部实体和关系来预测尾部实体。因为LLM中存有大量常识知识,也可以通过LLM构建知识图谱。LLM还可以补全知识图谱,提升原有的知识图谱的质量。
应当注意LLM此时的幻觉问题。
LLM作为内容翻译器(content interpreter)
LLM可以将输入信息理解后分析出一些内部信息,用于推荐。
LLM作为解释器(explainer)
LLM可以给出推荐某个物品的理由。通过这种方式可以提高模型的说服力和可靠性,也利于识别纠正错误。
相比于传统方法,LLM实现的可解释推荐能够不受模板约束,更加适合用户偏好的定制解释,减少局限性。此外,它也能获得用户即时反馈,促进双向对齐。
问题:无法找到给出解释的依据;给出的解释可能与推荐的行为不一致;同样的线索可能给出不同的解释。
LLM做推理
LLM拥有一定的推理能力,能够帮助挖掘用户兴趣。
LLM可以不做调整,直接进行推理推荐。但是存在问题:
- 在公开数据集上表现好,但私有数据集上表现差(zero shot);
- LLM与传统推荐模型的推荐性能拉不开差距。
此外,LLM还可以与其他算法结合(如遗传算法,LLM生成解空间中的可选解),从而获得比直接推理更好的性能,还能维持一定的可解释性。
存在的问题:复杂度比较高 等问题。
LLM作为对话代理
会话式推荐系统可以实时理解用户意图,根据反馈调整推荐。
LLM可以通过一系列QA获取用户偏好来进行推荐。同样的,存在一系列问题:针对私有数据的效果差,可通过微调解决;prompt仍然需要引导才能成功推理;长时间的记忆存在问题(retrieval)。
LLM用于工具学习(tool learning)
工具学习将专门工具与基础模型相结合,从而解决复杂问题。
LLM与外部工具(如数据库、搜索引擎等)相结合中,LLM常用作控制器,选择管理现有的模型解决问题。
LLM作为推荐代理时,也可以使用外部工具改善其缺少私有数据,或过时信息造成的问题。可用的工具有:搜索引擎,数据库,recommendation engine等。
LLM作为个性化内容创建者
使用LLM针对不同个体生成个性化内容,如视频,广告等。存在的问题:真实性,数据隐私。
仍然存在的问题
计算能力不足,响应时间长;
个性化任务需要特定的数据集,需要针对数据集做调整;
长文本的窗口限制;
解释性问题,不够透明,可能涉及公平与道德问题
个性化系统的评价指标问题:针对大模型可能需要新增评价指标,如用户偏好,满意度等;
个性化系统需要在性能、准确度之间做权衡。
LLM的一种个性化方法
文章名:Teach LLMs to Personalize – An Approach inspired by Writing Education
google实现
实现了一种个性化的文本生成的通用方法。
具体而言:多阶段多任务框架生成;检索-排序-总结-综合-生成。多任务:LLM应更好地阅读给定文本并理解其来源,才能生成更个性化的内容。
- 研究发现写作生成任务的效果与阅读理解任务相关。因此,模型还需要判断给定的一堆文档是否由同一个作者撰写。