以下是对一部分多模态相关论文的模型分析,包括ViT、CLIP、Swin Transformer、VLMo、BLIP、LLaVa。
ViT
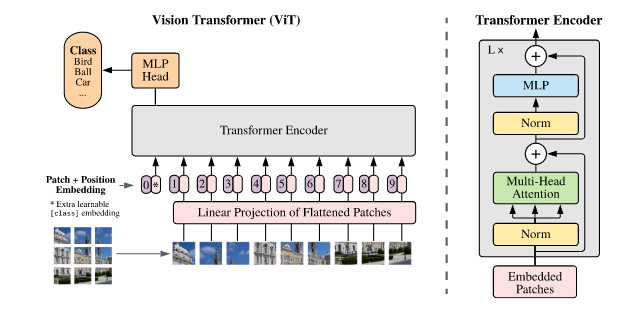
ViT的motivation是将Transformer应用到CV领域。这个想法的难点在于如何将NLP中token的embedding对应到图像中。
ViT对这个问题的解决方案是将图像划分为patches,例如将一张224x224x3的图像按长宽进行划分;假设每个patch的大小为14x14x3,则可以分成(224/14)^2=256个patch,并横向排成一个sequence,作为Transformer的输入。
上述操作可以得到图像的embedding,但存在的问题是:attention机制计算patches之间的attention score时,没有patches之间位置的信息。attention机制对所有图像块两两计算分数,因此两个patch交换顺序后仍然可以计算。因此,需要增加patch在图像中位置的编码。例如图像被分为9个patches,则给这9个patch编号1-9,并进行embedding,加到patch的embedding中,作为encoder的输入。
除此之外,为了匹配NLP任务中存在的[CLS]符号,在embedding输入encoder之前,还需要在最开始增加编号0的[CLS]embedding。
CLIP
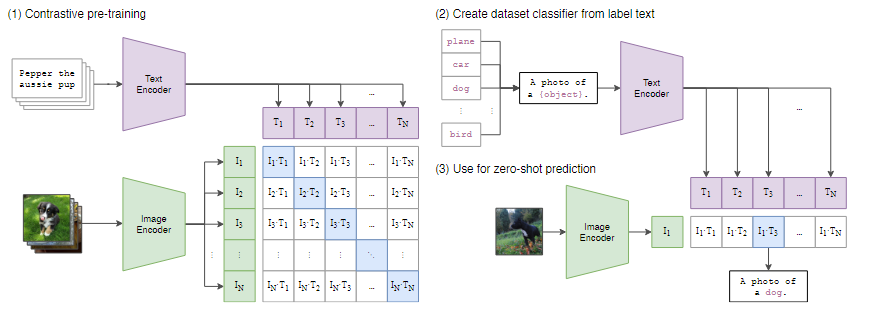
CLIP的motivation是使用Transformer做图文匹配。为此,他需要大量的图片文本对作为训练集。
CLIP的结构是将文本通过text encoder转换为embedding,将图片通过image encoder转换为embedding,最后计算这些embedding的相似度。
对于N个图片文本对,图片和文本的embedding可以构成两个张量:文本张量中$T_1,…,T_N$表示文本embedding,图片张量中$I_1,…,I_N$表示图片embedding。这两个张量中的embedding两两做内积,可以得到一个矩阵,表示相似度。
在这个相似度矩阵中,最理想的结果是对角线上元素为1,其他地方元素为0.计算交叉熵损失就可以得到差距,进而训练模型。
Swin Transformer
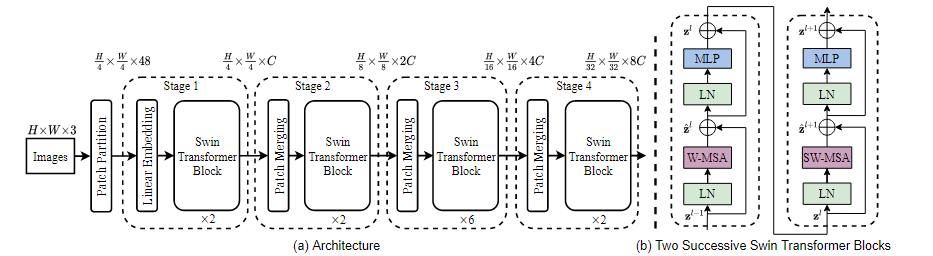
Swin Transformer的motivation是在ViT的基础上增强跨窗口能力。这可以通过移动窗口机制实现。
- Swin Transformer首先将图片划分为4x4的patch,将$H\times W\times 3$的图片划分为$\frac H 4\times\frac W 4\times (3\times 4\times 4)=48$的张量;
- C为超参数,上述张量通过线性映射到$\frac H 4\times\frac W 4\times C$的维度上;
- Swin Transformer Block不改变维度,进入第二个Block维度仍然为$\frac H 4\times\frac W 4\times C$;
- Patch Merging操作例:原来4*4矩阵,从上到下从左到右分别为1-16。现在将1 3 9 11合并为2*2矩阵,2 4 10 12合并,类似得到4个2*2矩阵
在channel上拼接(池化),得到$\frac H 2\times \frac W 2\times 4C$的张量,在经过1*1卷积将4C降为2C
移动窗口多头自注意力:
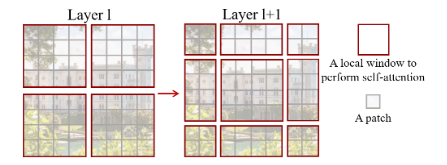
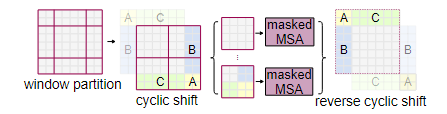
每次移动原窗口的一半,使得不同窗口之间可以进行信息交互。但移动窗口后,4个窗口会变成9个窗口,增加计算量。可以使用循环移位方法维持4个窗口不变,但增加掩码防止原本不相邻的位置计算注意力分数。
MoCo
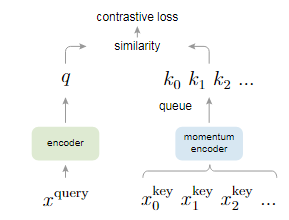
MoCo的motivation是使用对比学习的方式做自监督学习。对比学习可以理解为检索字典的任务,根据query的embedding在字典中查找正样本的key对应的embedding,这两个embedding应该相似;与负样本的key对应的embedding应该不相似。
对比学习中,字典大小决定了训练效果;字典应该越大越好。但字典过大会导致每次更新权重的计算量增加,很可能无法训练。为解决该问题,文章引入了队列,每次从队列中抽取一部分key计算相似度,更新encoder权重后计算embedding加入队列尾,从队列头取出元素计算loss。
但这样会引入另一个问题:队列中每个元素的embedding都是由不同状态的encoder计算得到的,这会导致不一致性。为解决该问题,文章引入了动量机制(momentum)更新权重;即:每次对于key更新权重都保留大量原始信息,只做很小的调整。即:
$$
\theta_k \leftarrow m\theta_k+(1-m)\theta_q
$$
其中$m$取值常为0.99。这样就保证了query encoder更新时,key encoder更新更缓慢,保持了队列元素的一致性。
DETR
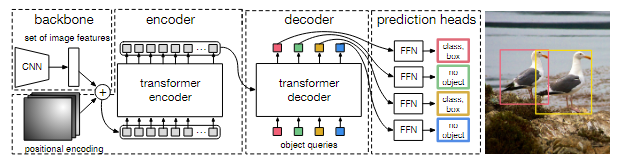
DETR的motivation是用Transformer做目标检测。在DETR之前的目标检测模型大多使用了非极大值抑制(non-maximum supression, nms)过程,导致模型复杂,超参数难调节。这篇文章没有使用nms过程,但仍然达到了较好的效果。
对于一张图片,DETR先生成N个框,再使用二分图匹配的匈牙利算法找到匹配最好的几个框,从而计算loss。具体而言,DETR的backbone模型是CNN(ResNet),抽取出图片特征后增加positional encoding,输入transformer encoder+decoder+FFN中生成预测的N个框,包括位置以及类别。在decoder阶段,transformer的输入是object queries,是可学习参数,用来引导生成目标框。
ALBEF
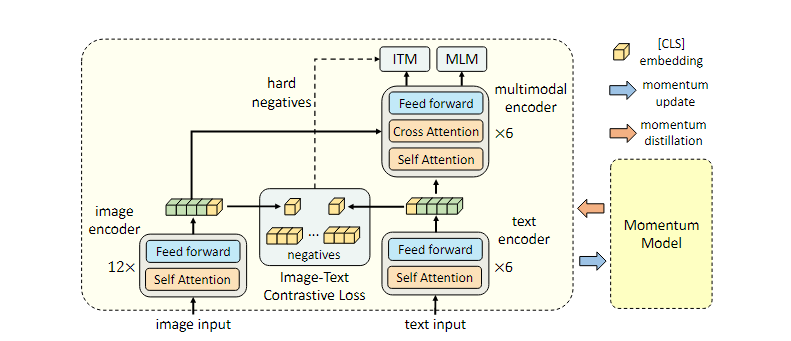
ALBEF是另一种学习图片与文本对齐的模型,与CLIP目的一致。
一般而言,图像比文本包含更多的信息,需要更深的网络提取特征。因此为了保持模型的规模与之前的模型可比,文章将文本encoder分为两部分,只用6层attention block作为text encoder,而图像的encoder仍然保持12层。
在12层的image encoder和6层的text encoder后,输入文本图像对的特征就已经被抽取出来了。每个文本图像对计算loss,就可以得到ITC loss。这个loss是在fusion之前计算的,即没有经过最后多模态encoder的计算就可以得到,因此这个loss就让image和text在fusion之前就进行了align,即标题。
ITM loss是经过fusion之后,在模型最后增加FC层,判断图像和文本是否在一个类这样一个二分类任物的loss。但实际上这个loss过于简单,因为负样本数量远远大于正样本,直接输出不属于一个类别准确率也很高。因此可以通过ITC loss得到最接近正样本的负样本(hard negatives),将这个负样本作为计算loss的根据,使得这个loss更加challenging。
MLM loss即BERT中对语句进行MASK操作后判断MASK掉的单词,从而计算loss。这次输入的text是被MASK的语句,但其他两个loss都是原始text,因此需要两次forward过程。
Momentum Distillation:因为数据noise很大,可能生成的负样本描述对图片也是一个很好的描述。因此需要构建一个momentum model,使用这个模型生成pseudo targets,使得one hot label变为multi-hot label。这样在训练时,如果原始label是错误的,或是noisy的时候,momentum label也可以提供帮助。这两个模型生成两个loss,通过momentum方式影响最终loss即可。
VLMo
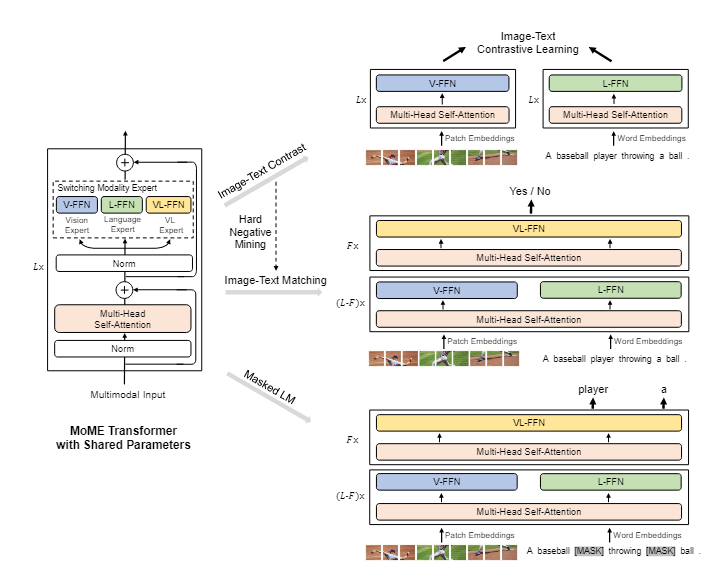
VLMo的motivation是发现:
- 以CLIP为首的双塔(dual-encoder)架构因为计算模态间交互只使用了矩阵乘法,在检索上很高效;但这种简单的交互面对复杂的情况难以建模;
- 单塔架构:仅对文本和图像进行相对简单的预处理得到embedding,在模态间交互时使用encoder进行建模。这种方式建模能力强,但推理慢(因为要通过encoder)。
因此将这两种结构进行结合,根据不同情景调用不同expert即可。(共享参数)
BLIP
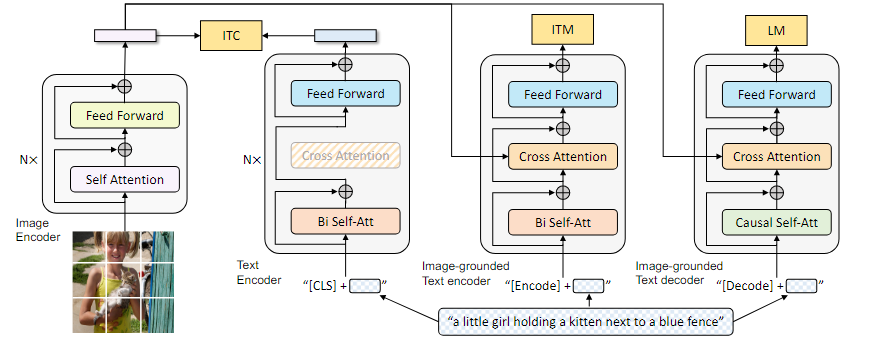
BLIP的motivation有两个角度:
- 模型角度:encoder only的模型可以进行图像文本retrieval,但不能直接用来进行文本生成(例如图像生成字幕);encoder+decoder的模型可以进行文本生成,但还未用到图像文本retrieval。如果使用一个模型将这些功能进行unify,将会提升功能。
- 数据角度:无论脏数据集的大小,其都会在一定程度上影响训练结果。
因此BLIP提出:可以在不同的应用上使用不同的模型,共享部分参数。结合了ALBEF和VLMo的特点。
图像仍然使用标准ViT模型,针对文本有3个不同encoder/decoder,包括:
- 对文本的text encoder,生成text embedding,可以用来和图像的embedding计算itc分数;
- 加上了图像信息的image-grounded text encoder,可以直接用来生成图文匹配结果(二分类);
- 类似GPT的生成模型image-grounded text decoder,可以借助图像和(初始)文本信息,生成符合图像信息的文本。
这三个文本模型中,前两个模型的self attention模块共享权重;后两个模型的cross attention模块共享权重;三个模型的feed forward模块共享权重。
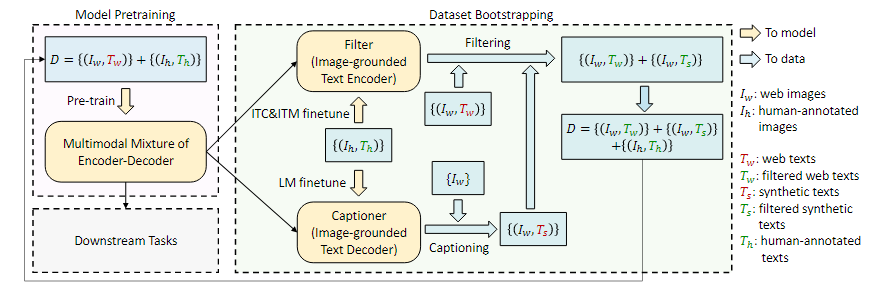
Captioning and Filtering:已知目前有大量的noisy数据集,该方法提供了一种消除噪音训练的方法。noisy数据集为${(I_w,T_w)}$图像文本对,其中$T_w$不可信;人工标注数据集为${(I_h,T_h)}$图像文本对,其中$T_h$可信。
- 首先使用这两种数据集训练,得到一个初步可用的网络;
- 将其中的image-grounded text encoder(即第一张图的第二个text模型)提出,作为filter;将image-grounded text-decoder(即第一张图的第三个text模型)作为captioner;
- 对于noisy数据集中的所有$(I_w,T_w)$数据对,都做以下操作:
- 使用filter对$(I_w,T_w)$做检验,如果不通过filter就删除;
- 使用captioner对$I_w$生成caption,成为新的$(I_w,T_w)$数据对,再经过filter检验;
- 只有通过filter的数据对才能保留。
- 通过上述方式,留下的数据对包括:
- 通过了检验的noisy数据集原始数据对$(I_w,T_w)$;
- 通过了检验的noisy数据集图片和captioner生成的caption数据对$(I_w,T_s)$;
- 人工标注的数据集原始数据对$(I_h,T_h)$。
- 留下的数据对质量更高,可以用来重新训练模型。
BLIP2
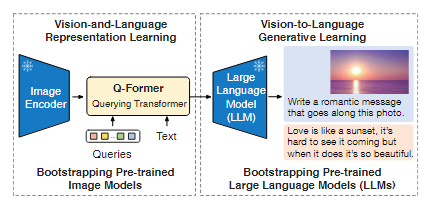
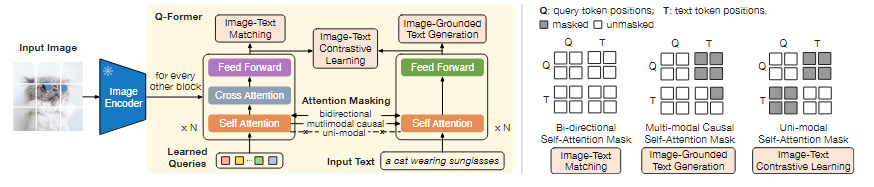
BLIP2的motivation是使用LLM作为模型的一部分时,如果冻结LLM参数,只训练其他部分,训练效率应该会提高。
不更新LLM参数代表着第一张图中image encoder和LLM冻结,但直接连接二者会导致特征空间不匹配,因此需要增加一个适配层,即Querying Transformer。训练Q-Former的过程仍然使用ITM等loss。
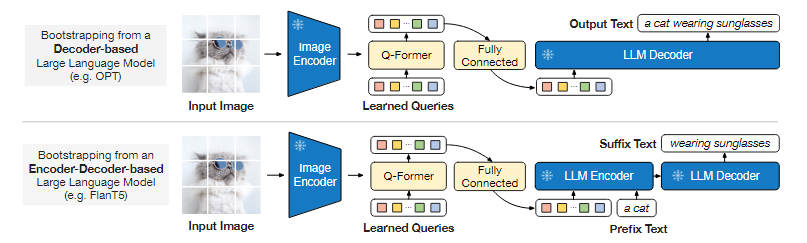
在生成任务中,因为Q-Former已经提取了图像的特征并转化为了语言模型的表达形式,因此通过一个全连接层就可以直接输入到预训练的encoder/decoder中,用于生成描述。生成描述既可以通过直接将embedding注入decoder来生成,也可以通过将embedding和实际文本的embedding结合,通过encoder+decoder结构来生成。
LLaVA/LLaVA-1.5
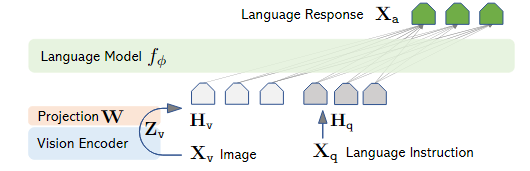
LLaVA关注点在于将image信息与LLM的文本输入信息对齐。图像在通过vision encoder得到其hidden state后,通过一个projection layer将其转化为text的hidden state,进而将image和text信息进行统一。
在文本处理中,如果涉及到图像信息,则将文本中的<image> token替换为图像的embedding即可。
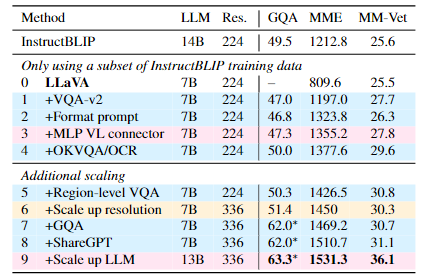
LLaVA-1.5使用了多种优化方式,例如更换更大的LLM、增加分辨率等,实现了更高的准确率。